Neu: Umwelt im Unterricht
Umwelt im Unterricht ist mit über 900 Inhalten die neuste Quelle im Angebot von WirLernenOnline.
zu den SuchergebnissenDie Community wünscht, WirLernenOnline liefert
Die Quelle des Bundesumweltministeriums veröffentlicht alle zwei Wochen Unterrichtsmaterialien zu aktuellen Themen der Umweltpolitik und Fragen der nachhaltigen Entwicklung. Die Materialien sind kostenlos und veränderbar (Open Educational Ressources, OER).
Die Open-Education Community, insbesondere die Fachredaktionen Nachhaltigkeit und Biologie, wandten sich an das Erschließungsteam von WirLernenOnline, mit dem Wunsch, die Inhalte im System auffindbar zu machen. Der Community-Wunsch wurde gehört, die Quellenerschließung konnte loslegen.
Freischaltung von Umwelt im Unterricht
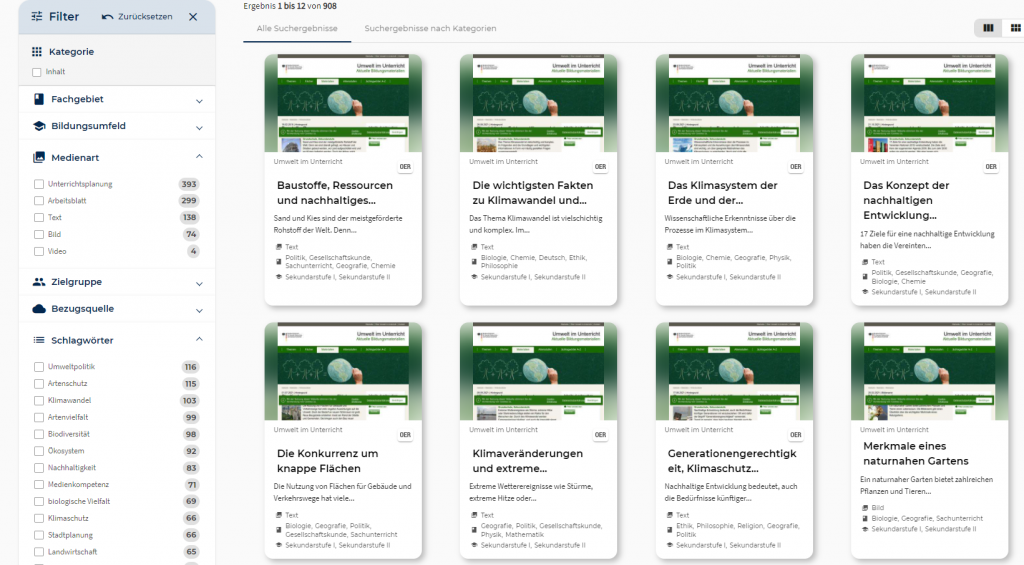
Der entwickelte Crawler liefert aktuell über 900 Bildungsinhalte von Umwelt im Unterricht. Diese wurden heute, nach der erfolgreichen redaktionellen Rohdatenprüfung, der Community zur Verfügung gestellt und veröffentlicht.
nOERdiges
Herausforderung: Crawlerbau
Da die Quelle Umwelt im Unterricht bisher noch nicht maschinell erschlossen wurde, musste der Crawler von grundauf neu entwickelt werden. Umwelt im Unterricht liefert keine von außen ansprechbaren APIs oder offene Schnittstellen zum Auslesen der einzelnen Bildungsinhalte. Die Herausforderung war also, dass der Crawler in der Lage sein muss, auf manuelle Weise durch die Webseitenstruktur von Umwelt im Unterricht zu navigieren. Der Crawlerbau erforderte daher den Bau eines soliden Navigationsalgorithmus durch die Unterebenen der Webseitenstruktur.
Qualitätsanforderungen beim Crawlerbau
Die Software-Lösung via Webcrawler muss mehrere Qualitätsanforderungen erfüllen: In erster Linie müssen die in der Quelle vorhandenen Metadaten reliabel extrahiert werden. Das heißt, wenn auf der Webseite der Quelle eine bestimmte Anzahl von Bildungsinhalten verfügbar ist, soll der Crawler diese auch mit all seinen Metadaten erfassen.
Weiterhin soll der Crawler eine Quelle „schonend“ durchlaufen, das heißt, der Algorithmus für die Webseitennavigation und das Traversieren der einzelnen Unterseiten und Topics soll sparsam mit HTTP-Requests umgehen und keine unnötigen Zugriffe auf dem Server der Quelleauslösen. Ein flüchtig gemachter Logikfehler im Crawler-Quellcode kann am Ende des Tages aufseiten der Webseitenbetreiber, die ihre Bildungsinhalte für das Crawling zur Verfügung stellen, reelle (Traffic-)Kosten verursachen oder schlimmstenfalls wie ein DDoS-Angriff aussehen.

Damit Letzteres nicht passiert, bringt das freie und Open-Source entwickelte Webcrawling Framework “Scrapy” mit einem „Dupefilter“, der doppelte Anfragen filtert, und einer „Autothrottle“-Funktion, welche die Geschwindigkeit sukzessiver Anfragen drosselt, nützliche Funktionalitäten von Haus aus mit, die der Entwickler in den Einstellungen des Frameworks steuern kann.
Bevor ein Crawler auf eine fremde Webseite losgelassen wird, muss zudem sichergestellt sein, dass dies rechtlich auch von den Webseitenbetreibern abgesegnet wurde. Viele Webseiten setzen auf eine „robots.txt“-Datei, in der sie URL-Pfade für Crawler sperren, um nicht unnötigem Traffic und ungewünschter Indexierung ausgesetzt zu werden. Glücklicherweise hält sich diese Praxis im Falle von OER-lizensierten Bildungsinhalten oft in Grenzen. Dennoch gehört es zu dem Quellenerschließungsprozess von WirLernenOnline, die Webseitenbetreiber einer jeden gecrawlten Quelle um schriftliche Zustimmung des Crawlingvorgangs zu bitten – auch um die große Arbeit anderer zu respektieren, erst recht, wenn diese kostenfrei allen Nutzern zur Verfügung gestellt wird.